MuleSoft Technical Guides

MuleSoft – GCP BigQuery


BigQuery connecter is an asset to LoB workers as it helps in combining datasets and make well-informed decisions. The capabilities of BigQuery connecter can help in deriving more reliable data insights for Line of Business workers. Google Cloud’s strengths are leveraged with the help of BigQuery connecter in MuleSoft Anypoint exchange
Pre-Requisites:
- BigQuery’s Service account to connect with MuleSoft.
- Service Account should have enough privileges to read/write the data from BigQuery’s table
Service Account Key Generation:
- Go to Google Cloud Platform
- From Left Navigation Select IAM & Admin, go to Service Accounts and then click on create Service Account.
-
- Create a Service Account by providing Service Account Name
- Grant Appropriate roles for this account
- After successful creation
- Go to Service Accounts. Click on Create Key from Actions
- Select Key Type as JSON and download the Key file.
- Place this file under muleproject/resources.
- This key file along with Project id, will be used while configuring Big Query Global Configurations.
Adding Google BigQuery Connector to Project:
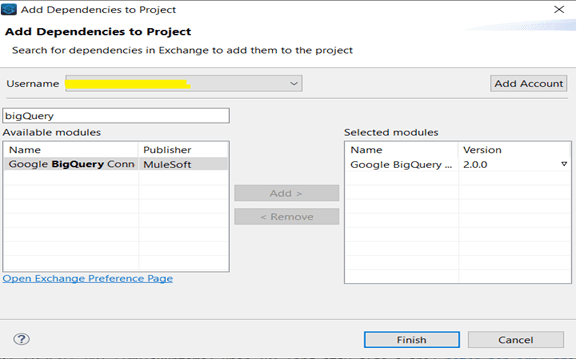
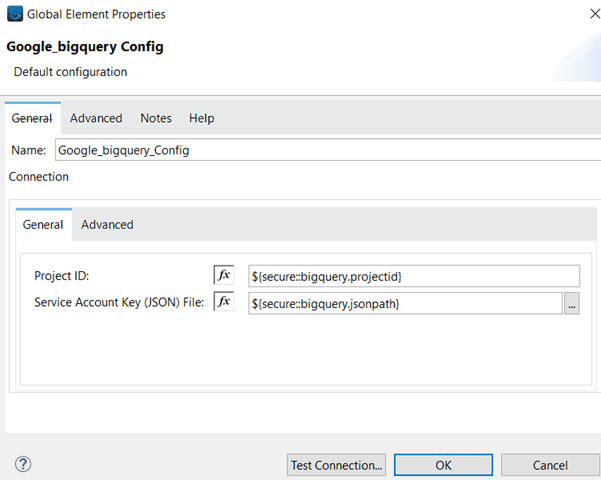
BigQuery global configuration:
Mule Snippet to
- Create Dataset
- Create Table
- Insert Data to Table
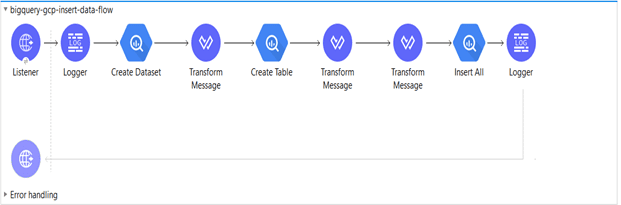
Code Snippet:
<flow name="bigquery-gcp-insert-data-flow" doc:id="fc6c9b26-2785-424a-8b67-73f90129d64c" > <http:listener doc:name="Listener" doc:id="04e93f87-271d-492a-baf5-407b620c3199" config-ref="HTTP_Listener_config" path="/bigQuery"/> <logger level="INFO" doc:name="Logger" doc:id="a1e22fea-114a-49b4-8976-102281bb0326" message="Inside GCP Flow"/> <bigquery:create-dataset doc:name="Create Dataset" doc:id="bf5677ff-b9ca-4c7e-821f-ffef95509315" config-ref="Google_bigquery_Config" datasetName="Test_1"/> <ee:transform doc:name="Transform Message" doc:id="0f730711-b450-4b87-9a59-3fe008968381" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/json --- [{ "FieldName" : "Name", "FieldType" : "STRING", "fieldDescription" : "This is name", "fieldMode" : "NULLABLE" }, { "FieldName" : "EmployeeID", "FieldType" : "STRING", "fieldDescription" : "This is Employee Id", "fieldMode" : "NULLABLE" }, { "FieldName" : "Age", "FieldType" : "INTEGER", "fieldDescription" : "This is Age", "fieldMode" : "NULLABLE" }, { "FieldName" : "ContactNumber", "FieldType" : "STRING", "fieldDescription" : "This is Contact Number", "fieldMode" : "NULLABLE" }, { "FieldName" : "Designation", "FieldType" : "STRING", "fieldDescription" : "This is Designation", "fieldMode" : "NULLABLE" }, { "FieldName" : "Salary", "FieldType" : "FLOAT", "fieldDescription" : "This is Salary", "fieldMode" : "NULLABLE" } ]]]></ee:set-payload> </ee:message> </ee:transform> <bigquery:create-table doc:name="Create Table" doc:id="04e12735-1f07-4341-a226-139c9b199ca0" config-ref="Google_bigquery_Config" tableFields="#[%dw 2.0 output application/java fun parseSchema(schema) = schema map ( item , index ) -> { fieldName : item.FieldName, fieldType : item.FieldType, fieldDescription : item.fieldDescription, fieldMode : item.fieldMode } --- parseSchema(payload)]"> <bigquery:table-info > <bigquery:table table="Employee" dataset="Test_1" /> </bigquery:table-info> </bigquery:create-table> <ee:transform doc:name="Transform Message" doc:id="e8312d6e-3e91-46a4-b751-6da842ca72f5" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/json --- [ { "RowId": "1", "Name": "AAAAAA", "EmployeeId" : "1234", "Age" : 25, "ContactNumber" : "11111111111", "Designation" : "SE", "Salary": 500000 }, { "RowId": "2", "Name": "BBBBBBB", "EmployeeId" : "2345", "Age" : 22, "ContactNumber" : "222222222", "Designation" : "SSE", "Salary": 1000000 }, { "RowId": "3", "Name": "CCCCCCCC", "EmployeeId" : "3456", "Age" : 29, "ContactNumber" : "3333333333", "Designation" : "LEAD", "Salary": 1500000 }, { "RowId": "4", "Name": "DDDDDDD", "EmployeeId" : "4567", "Age" : 27, "ContactNumber" : "444444444", "Designation" : "MANAGER", "Salary": 1900000 } ]]]></ee:set-payload> </ee:message> </ee:transform> <ee:transform doc:name="Transform Message" doc:id="b6830088-4b17-4dcd-874b-8e139d30bdb6" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/java --- payload map (( payload01 , indexOfPayload01 ) -> { Name: payload01.Name, EmployeeId: payload01.EmployeeId, Age: payload01.Age, ContactNumber: payload01.ContactNumber, Designation: payload01.Designation, Salary: payload01.Salary, RowID: payload01.RowId })]]></ee:set-payload> </ee:message> </ee:transform> <bigquery:insert-all tableId="Employee" datasetId="Test_1" doc:name="Insert All" doc:id="65ec4e0a-6123-4501-bb8a-02f28e1120df" config-ref="Google_bigquery_Config" rowsData="#[payload]"/> <logger level="INFO" doc:name="Logger" doc:id="3ba21798-7ad3-40d4-8825-616c5747ac2b" message="#[payload]"/> </flow>
Mule Snippet to
- Asynchronous Query data from BigQuery Table
- Delete Table
- Delete Dataset
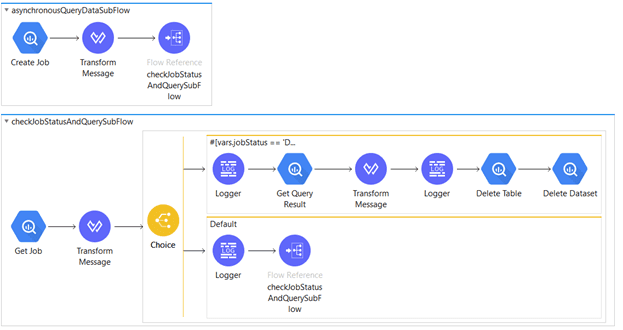
Code Snippet:
<sub-flow name="asynchronousQueryDataSubFlow" doc:id="32ed2391-90fe-4226-b17a-7d773c8a1fbd" > <bigquery:create-job doc:name="Create Job" doc:id="01b8a0ab-5729-435b-8198-59aa852426ed" config-ref="Google_bigquery_Config"> <bigquery:job-config > <bigquery:job-configuration > <bigquery:query-job > <bigquery:query-string >SELECT * FROM projectId.Dataset.Table</bigquery:query-string> </bigquery:query-job> </bigquery:job-configuration> </bigquery:job-config> <bigquery:job-info /> </bigquery:create-job> <ee:transform doc:name="Transform Message" doc:id="be6d3c42-13c4-44d4-abb1-beec17509789" > <ee:message > </ee:message> <ee:variables > <ee:set-variable variableName="jobId" ><![CDATA[%dw 2.0 output application/java --- payload.jobId.job]]></ee:set-variable> </ee:variables> </ee:transform> <flow-ref doc:name="checkJobStatusAndQuerySubFlow" doc:id="39feb8e6-5332-454b-b04f-81c03e91523a" name="checkJobStatusAndQuerySubFlow"/> </sub-flow> <sub-flow name="checkJobStatusAndQuerySubFlow" doc:id="c7b0f3aa-2c5a-4d4e-aa8a-3a36f84b95bb" > <bigquery:get-job doc:name="Get Job" doc:id="b5ee2576-76c5-4ba7-875e-b9a03021cc58" config-ref="Google_bigquery_Config" jobName="#[vars.jobId]"/> <ee:transform doc:name="Transform Message" doc:id="790f443c-78f8-4d01-bccd-f02a26f2425e" > <ee:message > </ee:message> <ee:variables > <ee:set-variable variableName="jobStatus" ><![CDATA[%dw 2.0 output application/java --- payload.status.state.constant as String]]></ee:set-variable> </ee:variables> </ee:transform> <choice doc:name="Choice" doc:id="0985c414-7340-4880-a03e-03d48127eae9" > <when expression="#[vars.jobStatus == 'DONE']"> <logger level="INFO" doc:name="Logger" doc:id="920b9287-bf97-4052-9d94-fb26e7fc81ab" message="#[vars.jobStatus]"/> <bigquery:get-query-result doc:name="Get Query Result" doc:id="983fb710-81a7-4f25-9581-153b551f9a02" config-ref="Google_bigquery_Config" jobName="#[vars.jobId]"/> <ee:transform doc:name="Transform Message" doc:id="be31d357-f6c8-4640-bc21-32ecad34ab8e" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/json var schema=payload.schema.fields --- payload.values map ((row, index) -> { (schema[0].name): row[0].stringValue, (schema[1].name): row[1].stringValue, (schema[2].name): row[2].stringValue, (schema[3].name): row[3].stringValue, (schema[4].name): row[4].stringValue, (schema[5].name): row[5].stringValue })]]></ee:set-payload> </ee:message> </ee:transform> <logger level="INFO" doc:name="Logger" doc:id="ae4bf21e-2809-4a22-a3f0-76228641ec94" message="#[payload]"/> <bigquery:delete-table doc:name="Delete Table" doc:id="350b3deb-1ea0-4f47-96b1-cf37322ff038" config-ref="Google_bigquery_Config"> <bigquery:table table="Employee" dataset="Test_1" /> </bigquery:delete-table> <bigquery:delete-dataset doc:name="Delete Dataset" doc:id="a02f15e3-fb4e-42e7-a38b-8989d06505d9" config-ref="Google_bigquery_Config" datasetId="Test_1"/> </when> <otherwise > <logger level="INFO" doc:name="Logger" doc:id="17f95175-9133-4173-b1b3-45ff1fd66e19" message="#[vars.jobStatus]"/> <flow-ref doc:name="checkJobStatusAndQuerySubFlow" doc:id="7916a719-dfa7-4051-aca2-37b7102446da" name="checkJobStatusAndQuerySubFlow"/> </otherwise> </choice> </sub-flow>
Mule Snippet to
- Synchronous Query Data.
- Dynamic Field mappings
Code Snippet:
<flow name="impl-process-get-details-flow" doc:id="a8c8480f-060e-4d6f-80c4-b3d1eace437e" > <bigquery:query doc:name="Query" doc:id="328aefbb-9399-425f-94b1-bd6d7016bb28" config-ref="Google_bigquery_Config"> <bigquery:query-job allowLargeResults="true"> <bigquery:query-string >#[payload.query]</bigquery:query-string> </bigquery:query-job> <bigquery:job-info-options /> </bigquery:query> <logger level="INFO" doc:name="Logger" doc:id="27ee05ed-3e39-46d7-9e73-8be89cc0e46e" message="Query executed" category="${logger.category}" /> <ee:transform doc:name="Transform Message" doc:id="59533f5f-7f9e-4ea3-ad57-a55b8f082124" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/json var schema=payload.schema.fields --- (payload.values map ((row, index) -> { "data" : (schema map ((schemarow, schemaIndex) -> { (schema[schemaIndex].name): row[schemaIndex].value })) reduce ($$ ++ $) })).data]]></ee:set-payload> </ee:message> </ee:transform> </flow>
Recent Blogs

NetSuite Integration using MuleSoft
NetSuite is a cloud-based enterprise resource planning (ERP) software suite that...…
Learn how MuleSoft & Salesforce helps businesses create incredible digital experiences. Speak with one of our consultants today
Let's Work Together