MuleSoft Technical Guides

DataWeave Streaming in Mule 4


What is DataWeave?
DataWeave is a powerful transformation language that has been introduced in Mule 4. DataWeave supports a variety of data formats, such as XML, JSON, and CSV. With DataWeave, we can transform the data from one format to another, apply filters, and do many other things. One of the key features of DataWeave is its streaming capability. In this blog, we will explore DataWeave streaming in Mule 4 and how it can be used to handle large amounts of data efficiently.
What is DataWeave streaming and how does DataWeave support Streaming?
DataWeave streaming is a feature that allows us to process large amounts of data without running out of memory. With DataWeave streaming, we can analyze enormous amounts of data effectively and process it in chunks, which means that we do not need to load the entire data into memory. Instead, we can process the data as it arrives in smaller chunks. This reduces memory usage with enhanced performance and allows us to handle big volumes of data efficiently.
DataWeave streaming can be used for both input and output data. We can use streaming for input data when we are reading large files and for output data when we are writing large files. We can also use streaming when we are processing data from an API or a database. By using streaming, we can handle large amounts of data efficiently and avoid running out of memory.
Using the streaming attribute in the input or output component:
We can use the streaming attribute in the input or output component to enable streaming. To enable streaming, we need to set the streaming attribute to true. Here is an example:
<file:read path="input.txt" streaming="true" />
In this example, we are using the file: read component to read a file. We have set the streaming attribute to true to enable streaming. This means that the file will be read in chunks, and we can process the data as it arrives.
Turning on deferred mode of our transform message:
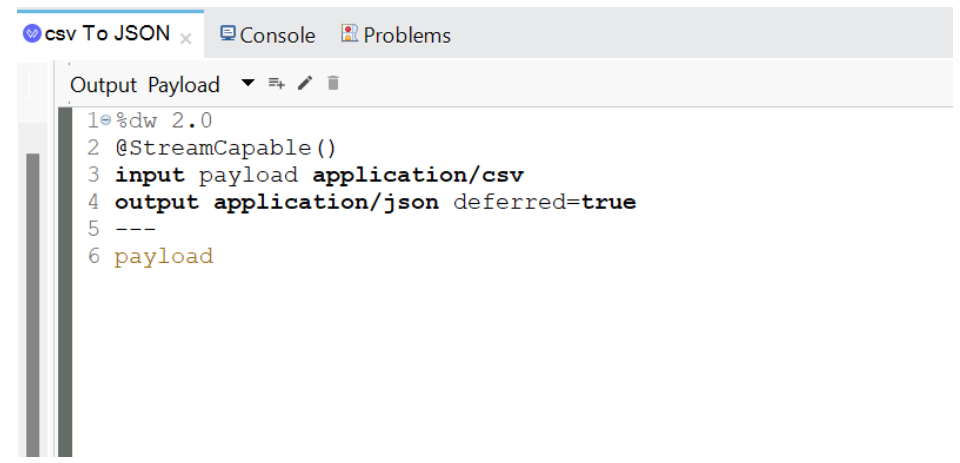
Mule 4 requires to turn on deferred mode of our transform message. The Streaming DW can transmit the streaming output data to the following message processor immediately when utilizing the deferred option. DataWeave in Mule can process data more rapidly and with less resource/memory usage, thanks to this behavior. Here is an example:
%dw 2.0
output application/json deferred=true
---
payload map ((value, index) -> {
"index": index,
"value": value
})
The fact that not all DataWeave operations enable streaming must be noted. Certain operations, such as sort, groupBy, and distinctBy, can only be utilized only if all the data is loaded into memory. You must load all of the data into memory and process it in a non-streaming way in order to use these methods
Streaming using DataWeave
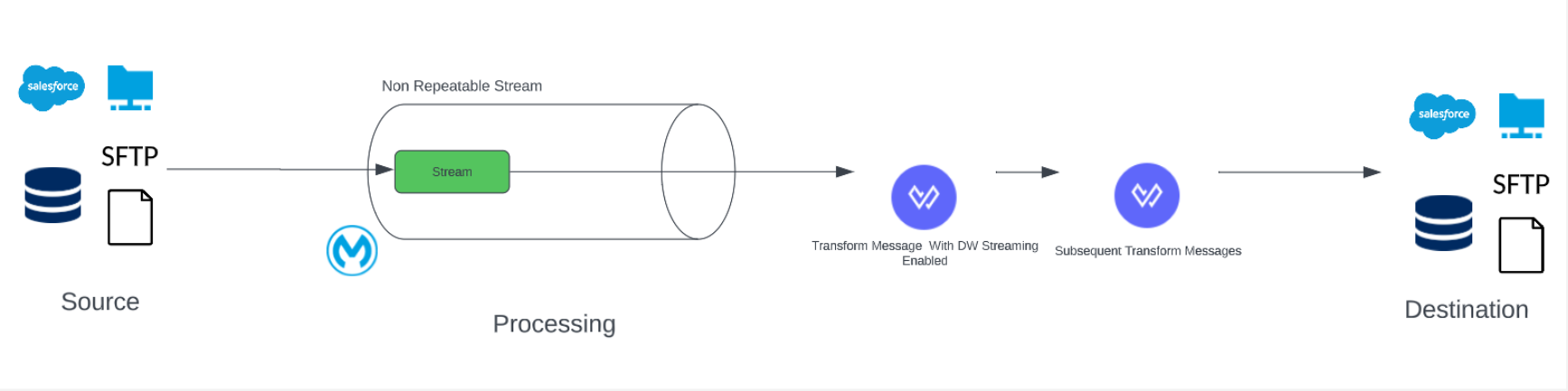
The non-repeatable stream cannot be consumed more than once. But, we can utilize DataWeave streaming to output the transform message’s result, which we can then use wherever. In this case, we are obtaining the data as a non-repeatable stream from the source and using it in the transform message’s deferred mode. Doing the transformation solely on that specific stream or payload, then sending the data to the next processor or transform message to complete the processing before transferring it to its final location.
When the deferred mode is enabled, the transform message accepts the stream but does not consume it; instead, it processes the stream and passes it on to the subsequent processors.
The way the streams are arriving must be the only way we utilize them; we cannot use them in any other way. By doing this, we may take advantage of the non-repeatable stream’s high degree of optimization.
Types of DataWeave Streaming
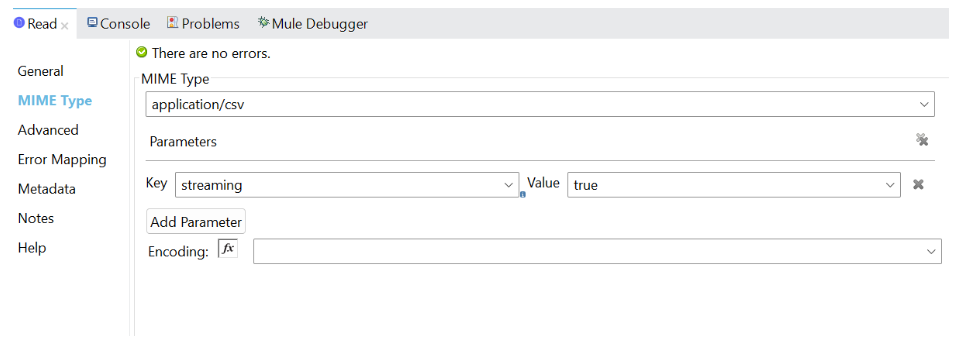
When it comes to DataWeave streaming only json, xml, and csv are permitted as data formats. As a result, you may profit from DataWeave streaming anytime our input data is in these formats. To identify the sort of data we have, we must describe the MIME type in the connector.
We must additionally specify the streaming parameter for all three of the parameters and set it to true. Nonetheless, because of the complicated xml structure’s potential for having distinct collections, we also need to set the classpath for xml. Thus, we must specify which specific collection must have streaming enabled in the xml document.
How to enable streaming?
It must be noted that default settings do not permit streaming. To stream data in a format that is supported, you can use the following two configuration properties:
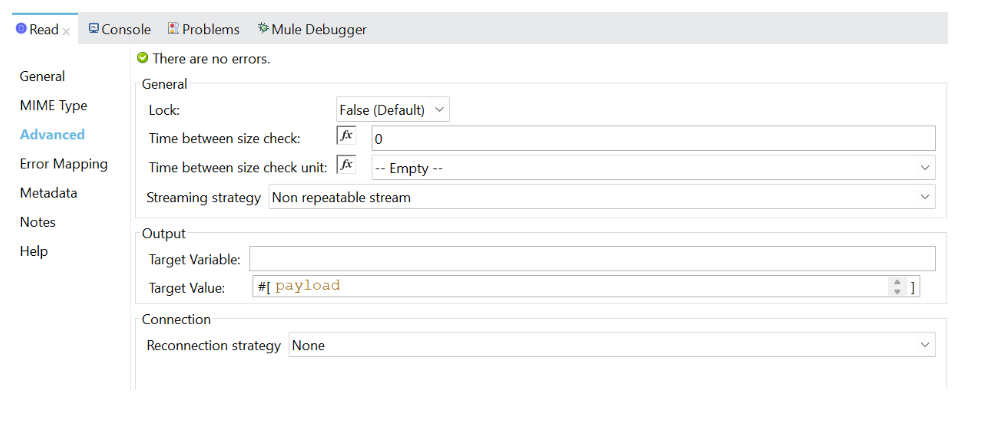
a. For reading source data as a stream, pass the streaming parameter as true and select the Non-repeatable stream option in the connector configuration.
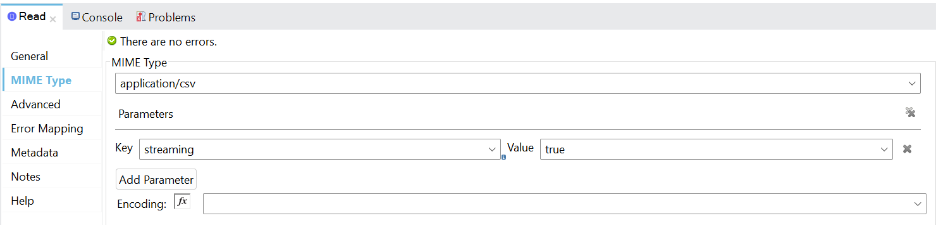
b. It is necessary to set the deferred attribute to true in the subsequent transform message for DataWeave to receive source data as a stream. The deferred writer attribute allows an output stream to be sent immediately to the flow’s subsequent message processor.
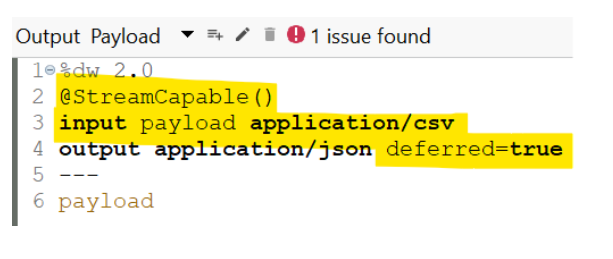
What is @StreamCapable()?
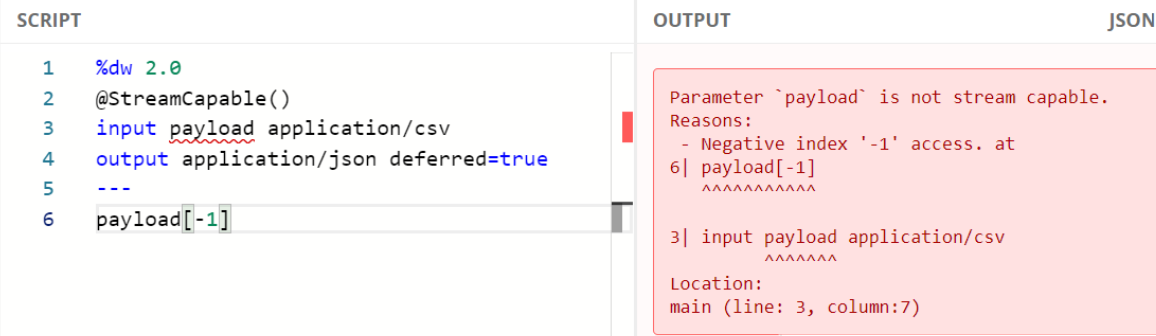
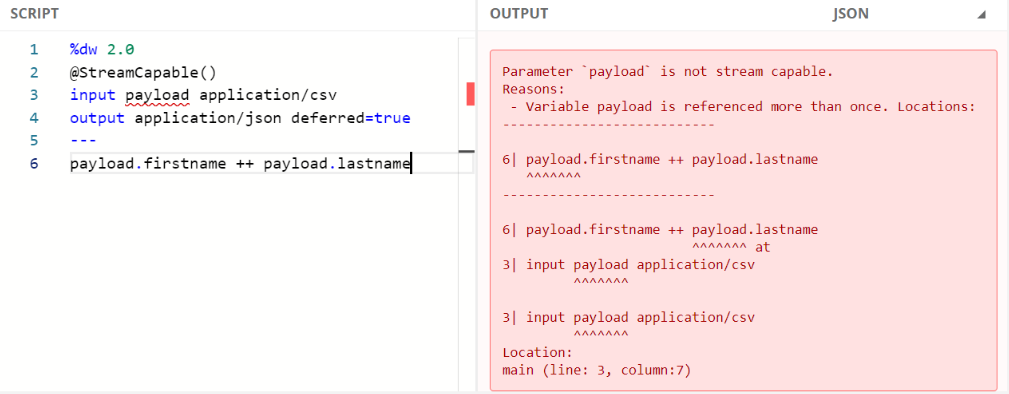
1. To ensure that our DW script complies with streaming requirements and the input data is streamable we can use the @Stream Capable() validator. It checks the following conditions:
● The variable must be used only once.
● Negative access of streams which are already passed, such as [-1] should not be allowed.
The chosen data is streamable if all the requirements are satisfied.
2. The DataWeave script must utilize an input directive that specifies the MIME type of the data source, such as input payload application/xml, in order to comply with the @StreamCapable() annotation.
Here are the examples:
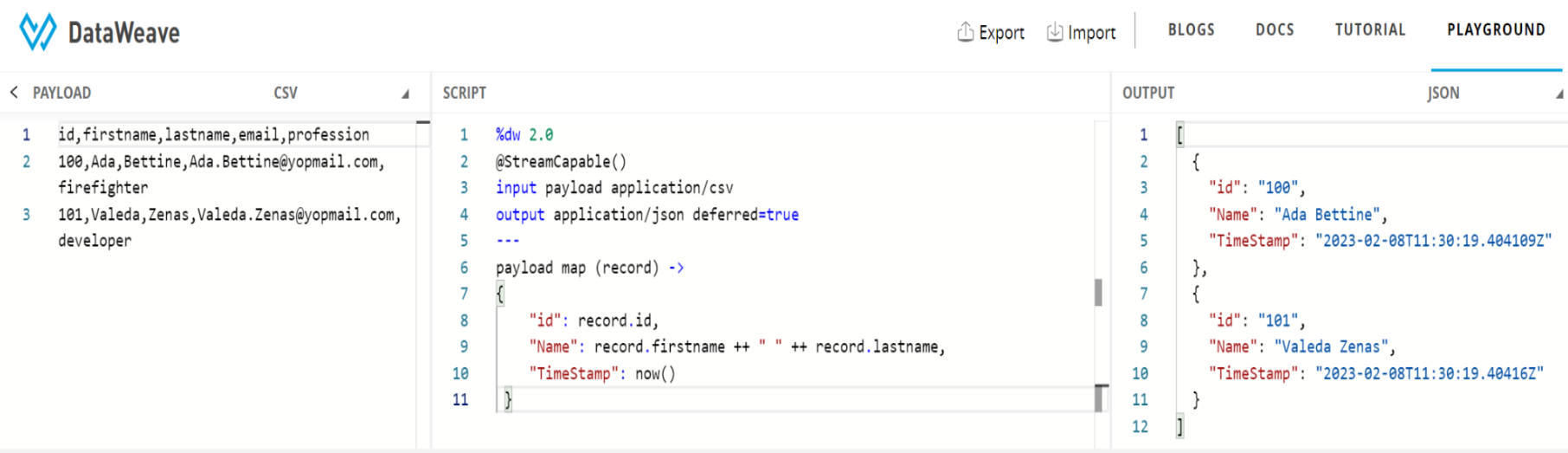
No index selector is set for negative access such as [-1] :
The variable can be referenced only once:
DataWeave Streaming DEMO
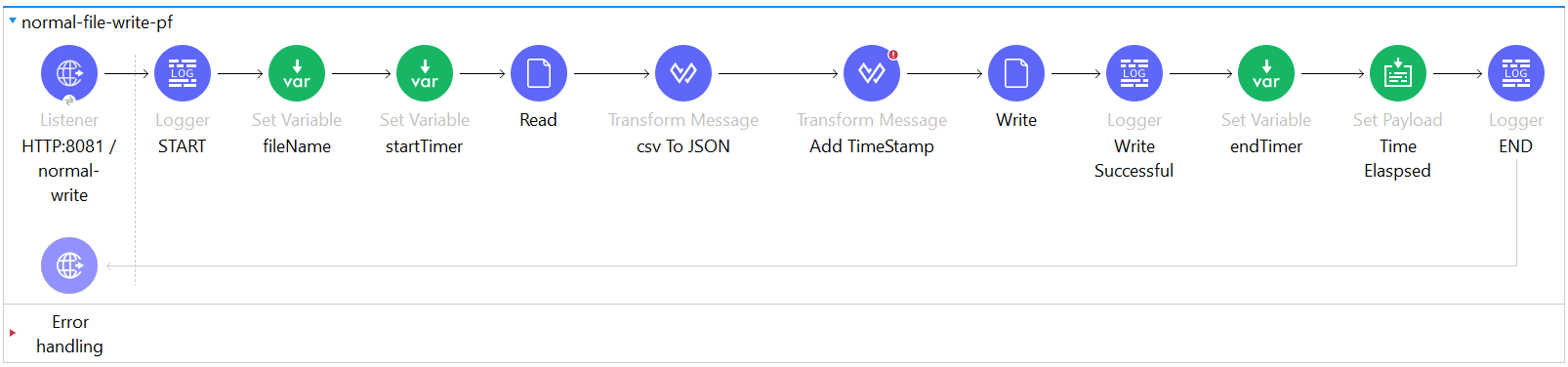
Case 1: Without Streaming
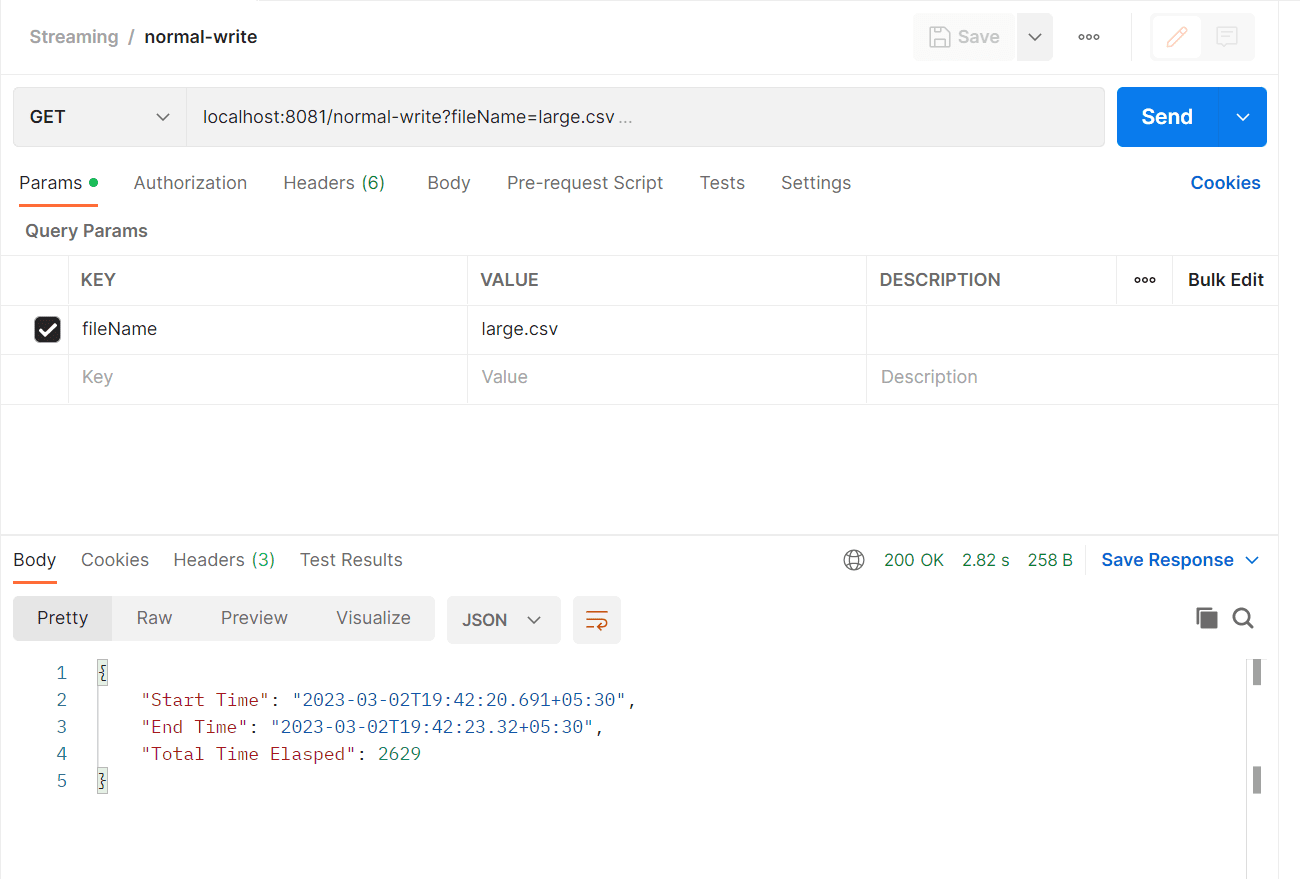
Here, we are reading the file, transforming it, and writing it into another file. The fileName is defined in the setVariable using queryParameter, and the file is then read using the “File Read Connector.” As we are not sending any parameters, MIME type, or enabling deferred mode, we are not using DataWeave streaming in this case. Instead, we are using the repeatable file store stream, which is a default streaming approach. As a result, the file read payload’s output will not be streamed in this case, thus more processing time.
Output:
Case 2: Using DataWeave Streaming
In this instance of DataWeave Streaming, we’re declaring the MIME type, adding the parameters, and activating the deferred mode. We’re also utilizing the non-repeatable streaming strategy, which allows us to transmit the stream to the final destination without consuming it.
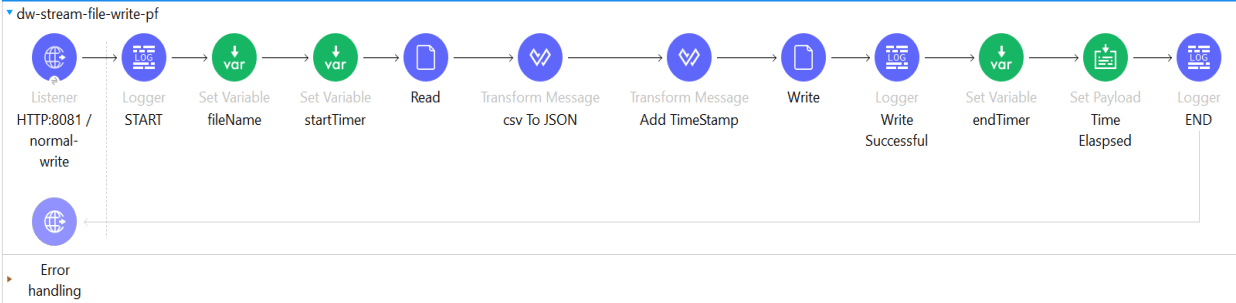
Output:
Transform Message:
Output:
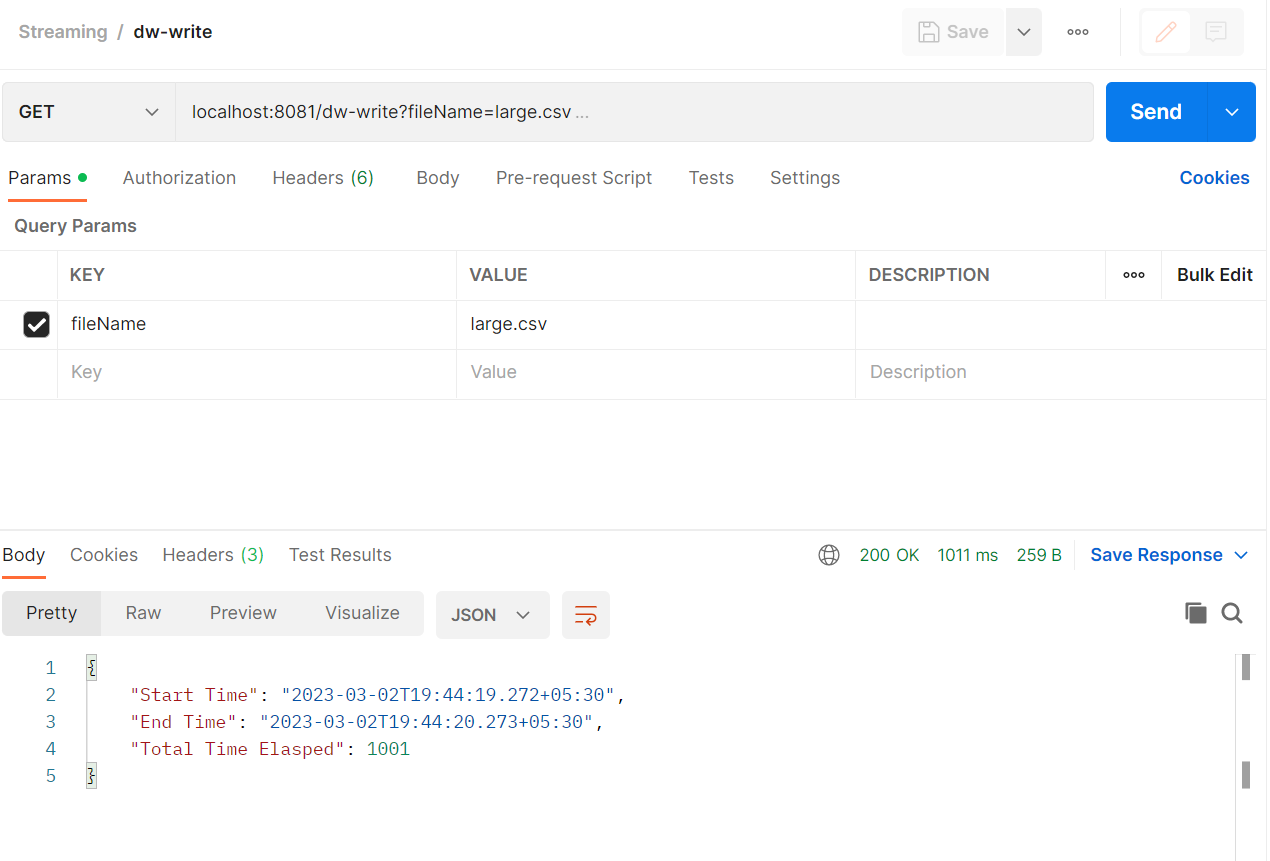
Hence, reading a file would take less time if DataWeave streaming were used.
Processing Large Datasets using Batch Jobs with Streaming:
- The Batch Job component automatically separates source data and puts it into permanent queues, allowing for the dependable processing of huge data volumes.
- Without streaming, Mule 4 batch jobs may perform less effectively. Instead of waiting for a batch of data to collect before processing, streaming enables data to be processed as it comes in real time.
- This can increase processing effectiveness and speed while also lowering the amount of memory needed to hold the data being processed.
- Without streaming, batch tasks must process the whole batch at once, which can increase processing time, use more resources, and decrease overall efficiency.
Conclusion:
In this blog, we have explored DataWeave streaming in Mule 4 and how it can be used to handle large amounts of data efficiently. We have seen how to use streaming for input and output data, and how to configure streaming in Mule 4. We have also seen a proof of concept that demonstrates how to read a large file and transform it using DataWeave streaming. With DataWeave streaming, we can process large amounts of data without running out of memory, which makes it a powerful tool for data transformation and processing.
Recent Blogs

Message Queue Driven Architecture in MuleSoft using Amazon SQS.
Whenever we are building complex systems using microservice architecture, we oft...…
Learn how MuleSoft & Salesforce helps businesses create incredible digital experiences. Speak with one of our consultants today
Let's Work Together