MuleSoft Technical Guides

Batch Processing of large data in Mule 4


What is Batch Processing?
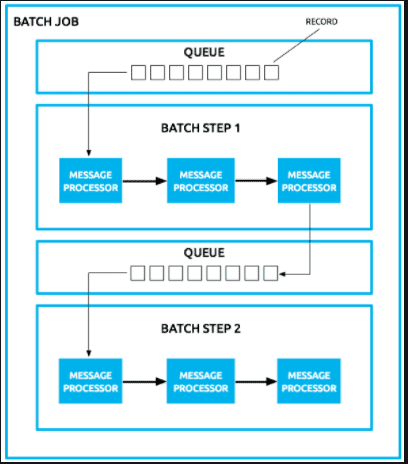
Batch Processing is the concept of processing a large number of records into batches. Batch processing can be executed without end-user interaction.
Why do we need Batch Processing?
If a document contains 1000 plus lines and a person wants to read all that File rather than going through the individual record one by one we can generate separate files for him by filtering out the records on some particular basis. By achieving this, the efficiency of a person would increase to process a large number of records. Any MuleSoft developer can easily process a large number of records with the help of batch processing.
How will it help in real-life scenarios?
This concept of batch processing is fantastic in itself. It is the next step to business automation. With the help of MuleSoft, we can process a large number of records parallel and asynchronously just in seconds. We can relate this concept to a few real-time scenarios like:
Scenario 1
Processing a single file with all information of registered users with HDFC Bank Credit Card to convert into individual files according to names of the user, that will contain all the information of users shared in the records of the bank in a single file.
Scenario 2
Handling large quantities of incoming data from APIs into outdated computer systems, yet still in use.
What will readers achieve after going through this blog?
This blog will facilitate a conceptual understanding of batch processing to MuleSoft developers. After going through this, a person would understand the need and benefits of batch processing and how it is helpful in real-time and how it is a b2b solution. Batch processing would make our work more comfortable and more categorized rather than being a bulk of data.
Implementation
Step 1: Make sure you have MuleSoft Anypoint studio 7+ installed on your system.
Step 2: Make a new project in your Any point Studio by clicking on File>New>Mule Project.
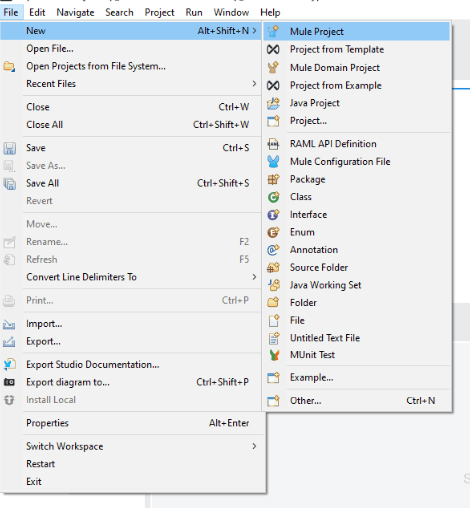
Step 3: Name your Project as batch_processing_records.
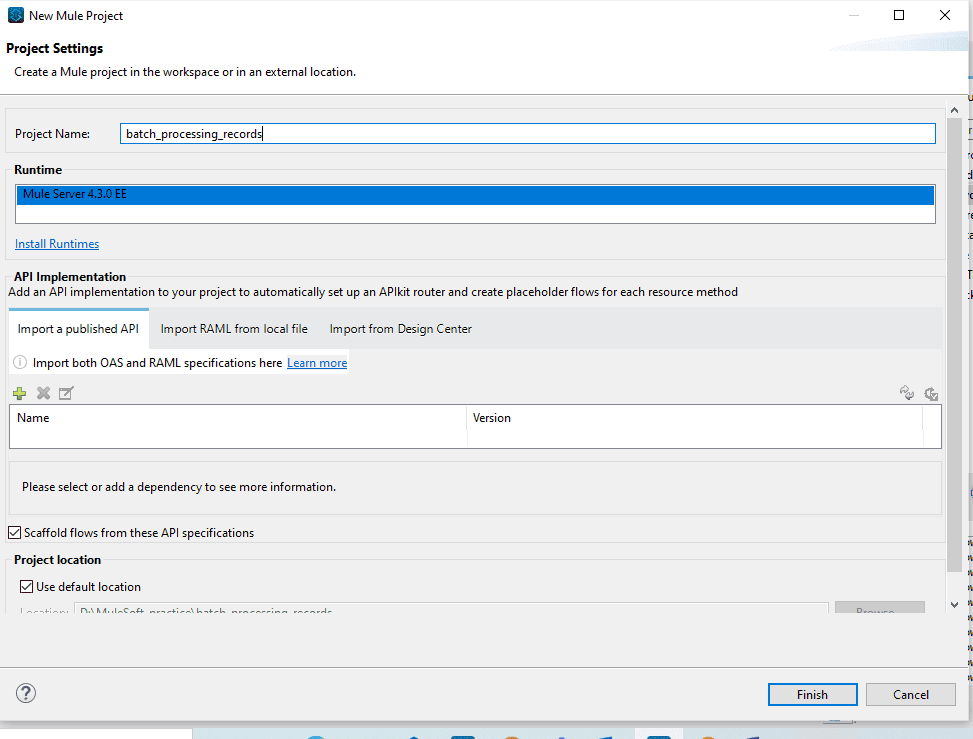
Step 4: Add file module by clicking on add module in the mule pallet as Add Modules>File.
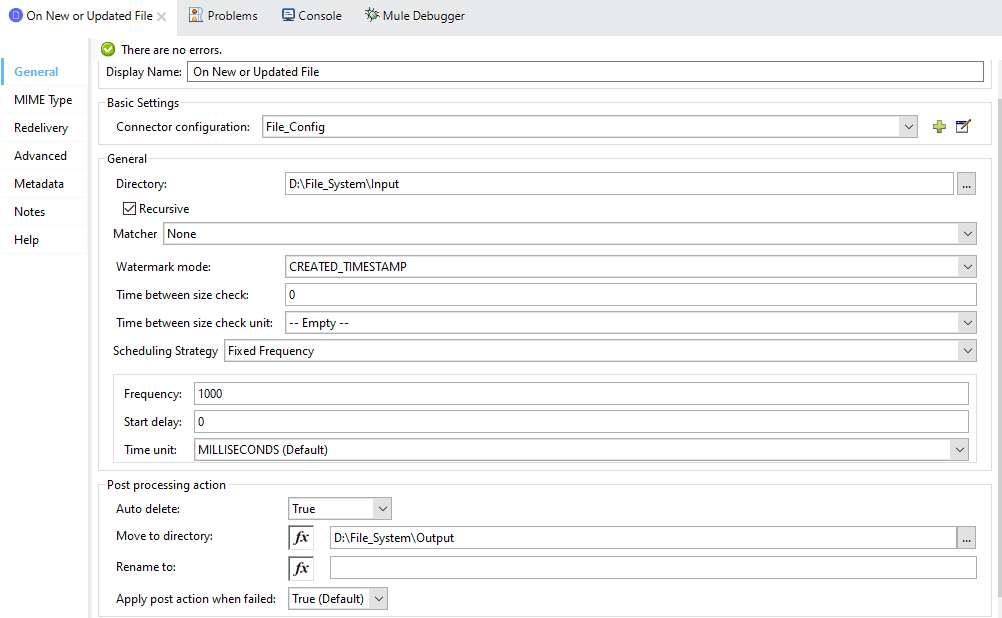
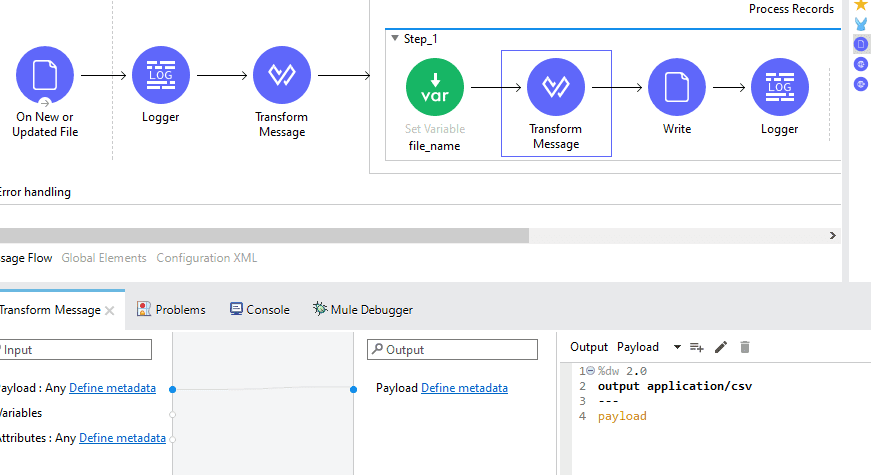
Step 5: Make the desired flow with the required components shown in the flow below.

Step 6: Set various connectors configuration as below.
For the component On New or Updated File set the configurations as below.
For the transform Message component set the configurations as below
Expression in DataWeave 2.0
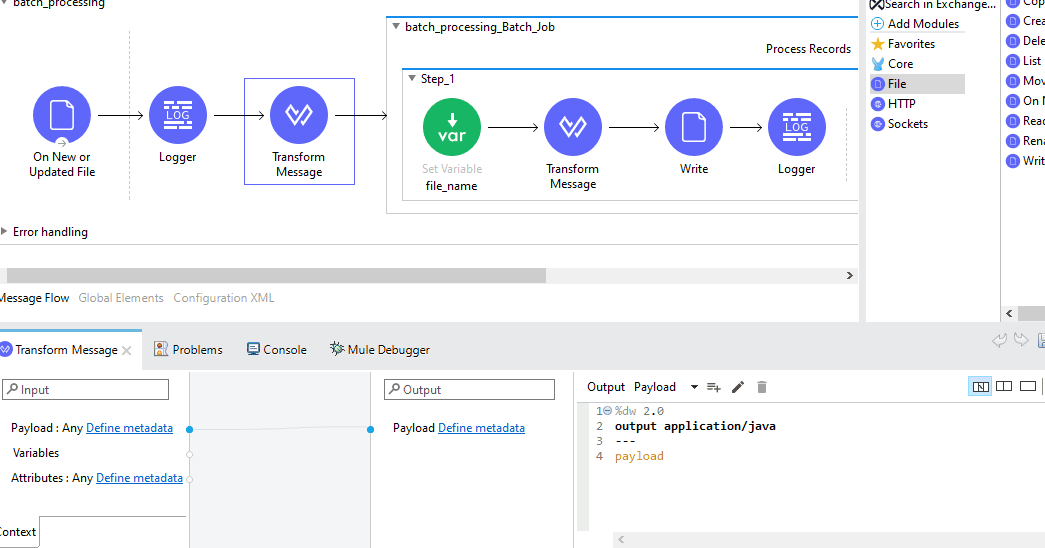
For the component Set Variable(file_name) set the configurations as below:
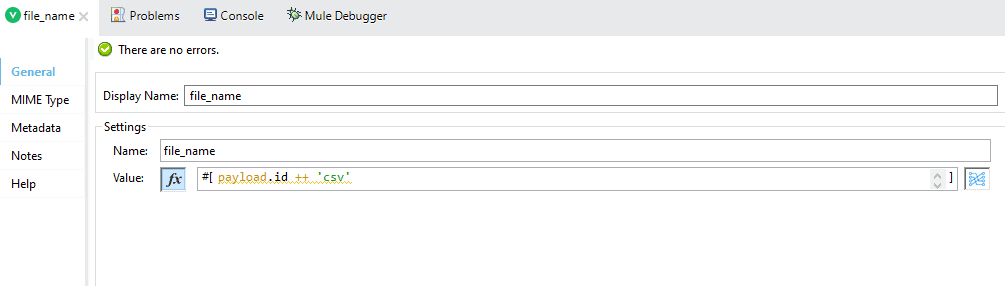
For the transform Message component set the configurations as below:
Expression in DataWeave 2.0
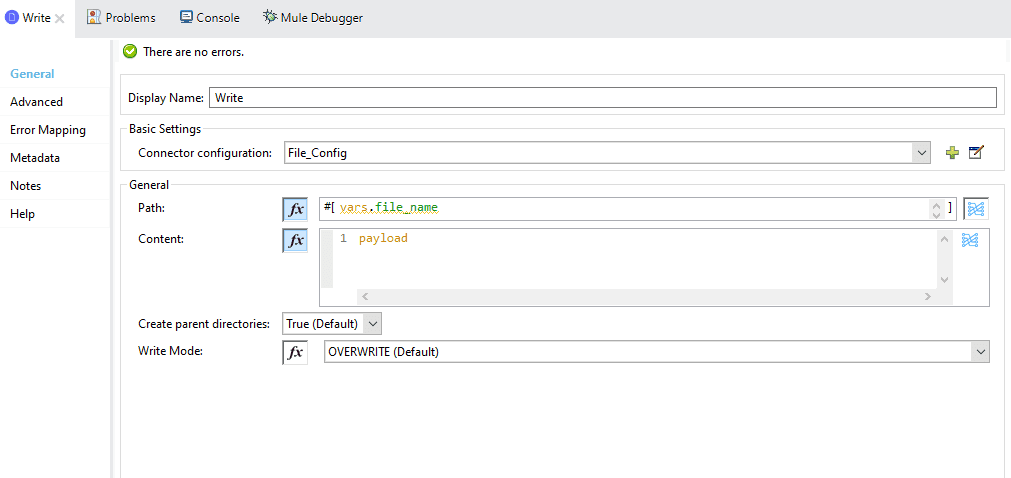
For the Write component set the configurations as below:
You can copy the XML code from below:
<?xml version="1.0" encoding="UTF-8"?> <mule xmlns:file="http://www.mulesoft.org/schema/mule/file" xmlns:batch="http://www.mulesoft.org/schema/mule/batch" xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd http://www.mulesoft.org/schema/mule/ee/core http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd http://www.mulesoft.org/schema/mule/batch http://www.mulesoft.org/schema/mule/batch/current/mule-batch.xsd http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd"> <http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" doc:id="cc7bbdfa-de77-4dd5-aa23-1ab3aeb1eb1b" > <http:listener-connection host="0.0.0.0" port="8081" /> </http:listener-config> <file:config name="File_Config" doc:name="File Config" doc:id="aed1f45e-df19-495d-9ff7-7c7eb08d01d5" > <file:connection workingDir="D:\File_System" /> </file:config> <flow name="batch_processing" doc:id="38e88733-12f4-43d6-8021-c07969ff37b0" > <file:listener doc:name="On New or Updated File" doc:id="4a37d3a6-3707-47dd-9919-d526b71637d2" config-ref="File_Config" directory="D:\File_System\Input" autoDelete="true" moveToDirectory="D:\File_System\Output" watermarkMode="CREATED_TIMESTAMP"> <scheduling-strategy > <fixed-frequency /> </scheduling-strategy> </file:listener> <logger level="INFO" doc:name="Logger" doc:id="d0dd5122-6069-49a7-a462-b89ab2295d97" message="#[payload]"/> <ee:transform doc:name="Transform Message" doc:id="e02c6428-20b8-4779-b031-14464ceeab56" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/java --- payload]]></ee:set-payload> </ee:message> </ee:transform> <batch:job jobName="batch_processing_Batch_Job" doc:id="841dfd5d-0606-4f7b-9eb6-908695bda417" > <batch:process-records > <batch:step name="Step_1" doc:id="57539532-dcbd-46a8-a8d5-bd114f85ec2e" > <set-variable value="#[payload.id ++ '.csv']" doc:name="file_name" doc:id="277d47c2-b38c-418d-983f-ca77db75fe18" variableName="file_name"/> <ee:transform doc:name="Transform Message" doc:id="5cc72a4c-77b3-4618-b152-d91585f00d83" > <ee:message > <ee:set-payload ><![CDATA[%dw 2.0 output application/csv --- payload]]></ee:set-payload> </ee:message> </ee:transform> <file:write doc:name="Write" doc:id="d3c595c1-235e-4728-9c89-47958cef18e3" config-ref="File_Config" path="#[vars.file_name]"/> <logger level="INFO" doc:name="Logger" doc:id="b06d8775-3389-4ff0-97c8-766d262a1740" message="In step1"/> </batch:step> <batch:step name="Step_2" doc:id="a67af3e7-b4ef-4f5d-9b58-a96516303e5f" > <logger level="INFO" doc:name="Logger" doc:id="8341f54c-1e17-4a3d-8073-97cd3ba1eb7a" message="In step 2"/> <batch:aggregator doc:name="Batch Aggregator" doc:id="876e9147-3e9b-4667-a3df-1cfff2f5f240" size="3"> <logger level="INFO" doc:name="Logger" doc:id="042bd23f-3f9e-4abc-917a-4008b7a1e99f" message="In step2 aggregator"/> </batch:aggregator> </batch:step> </batch:process-records> </batch:job> </flow> </mule>
Below is the snippet in Debug mode:
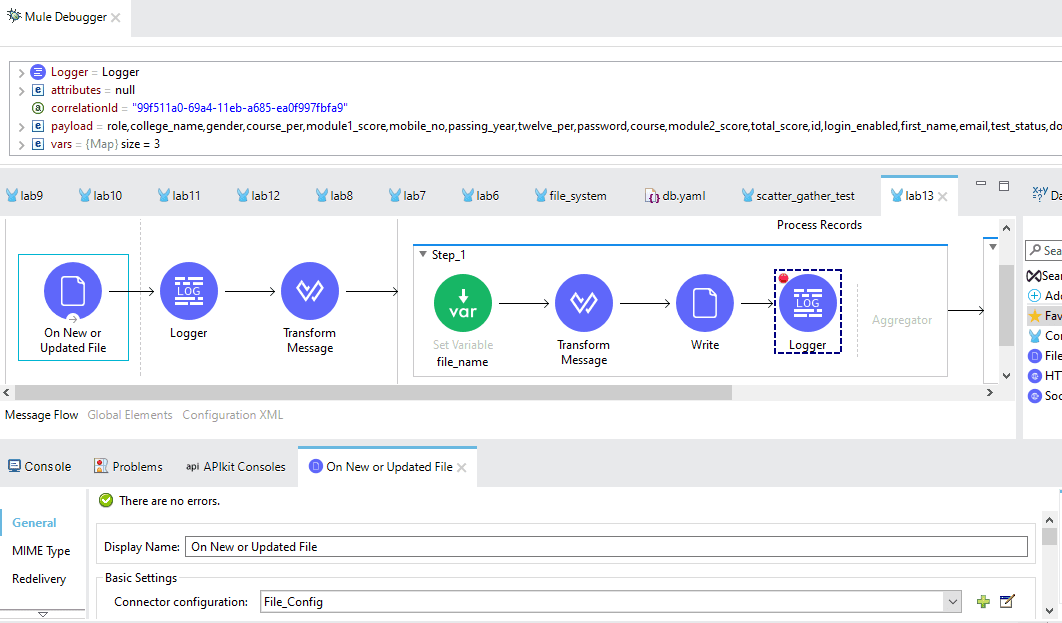
Snippet from the Input File:
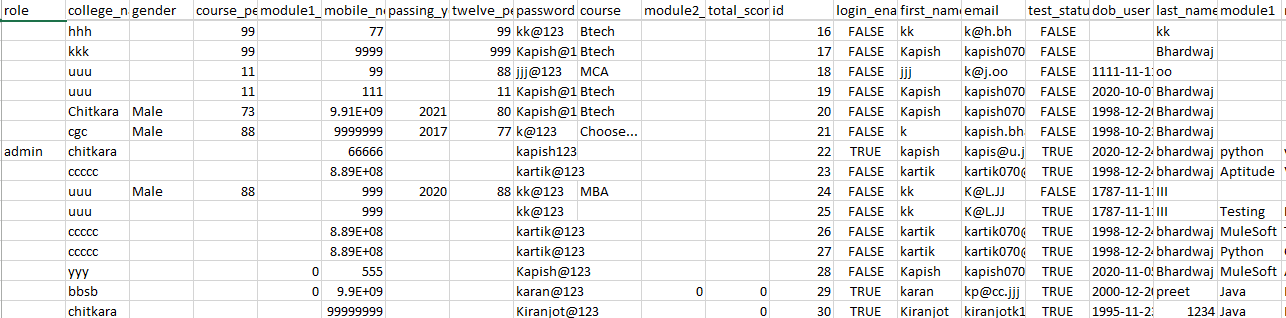
Snippet from the Output File:
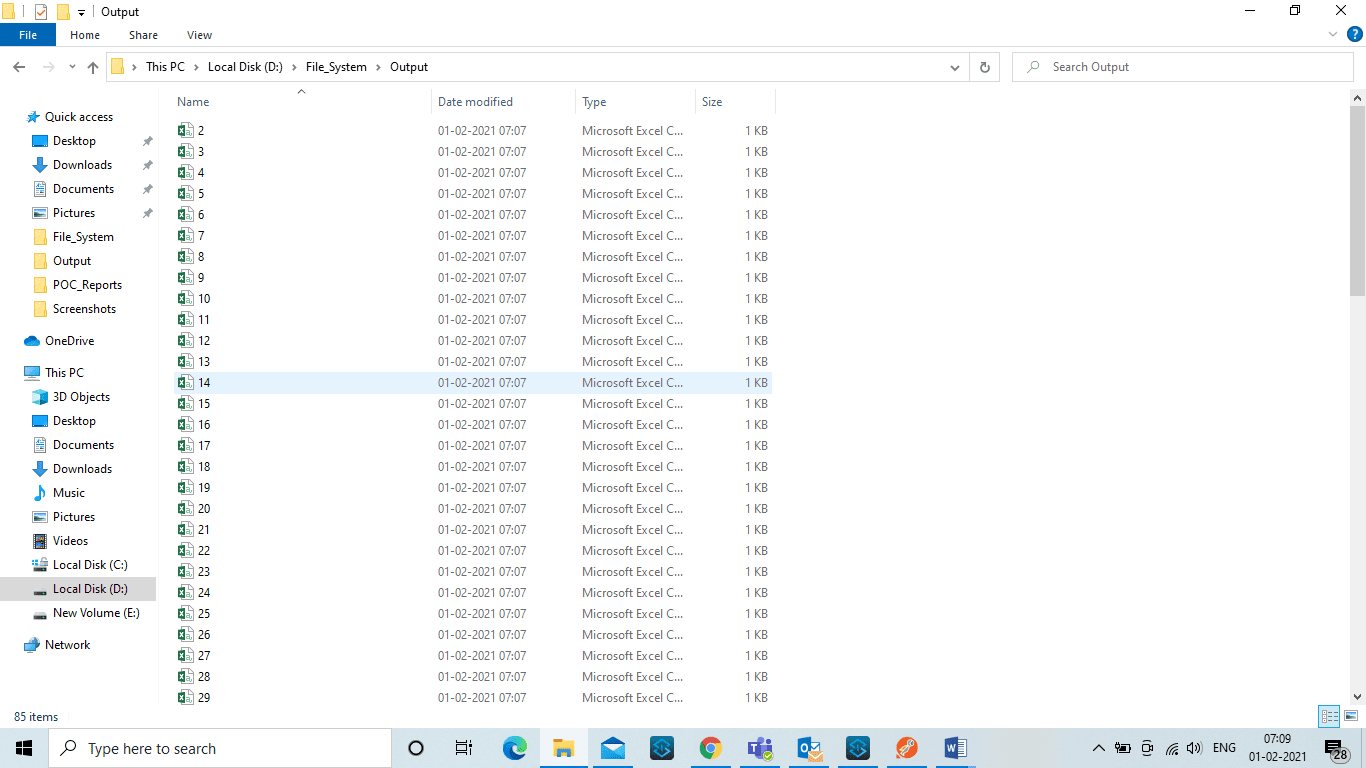
MuleSoft architecture:
Wrapping Up:
Batch processing helps to process records at a very high pace. Processing a single record to another in an incremental way takes a lot of time. It is an asynchronous process of processing records and hence improves the entire process’s agility and efficiency.
Recent Blogs

Understanding Salesforce Flow Approval Processes
Introduction: Salesforce introduced Flow Approval Processes in the Spring '25 re...…

Capturing Real-time Record Updation Using LWC
Introduction In modern CRM ecosystems, real-time Salesforce integration and s...…

All About Schedulers: Mule 4
In the world of Mule 4, automating repetitive tasks and triggering flows at defi...…

Demystifying CloudHub 2.0 Networking
CloudHub 2.0 is the latest version of MuleSoft's powerful managed runtime platfo...…
Learn how MuleSoft & Salesforce helps businesses create incredible digital experiences. Speak with one of our consultants today
Let's Work Together