MuleSoft Technical Guides

Architecting Scalable Integrations with CQRS Pattern in MuleSoft


Modern integration and distributed systems demand scalability and modularity. As systems become increasingly modular and API-led, traditional Monolithic service models struggle to keep up with real-time demands, concurrent transactions, and complex business logic, ultimately hindering organizational agility.
The CQRS pattern is gaining traction among architects, especially in platforms like MuleSoft, as a powerful approach to scaling integrations efficiently, reducing system load, and streamlining operations. Read the blog to gain a deeper understanding of the CQRS Pattern and its impact on MuleSoft Integration Architecture.
What is the CQRS Pattern?
CQRS (Command Query Responsibility Segregation) is a software architectural pattern that splits application responsibilities and separates write operations (commands) from read operations (queries), allowing both to scale independently.
- Commands modify data (e.g., create, update, delete) and often involve validation and business logic.
- Queries retrieve data without changing it, typically optimized for speed and caching.
By isolating these concerns, developers gain control over optimization strategies for each path, particularly valuable in integration-heavy environments like MuleSoft. This makes CQRS useful in real-world scenarios where microservices need to manage a high volume of simultaneous transactions effectively.
Why Use CQRS in MuleSoft Integration Architecture?
As a leading integration platform, MuleSoft supports API-led connectivity, microservices, and distributed system design. CQRS complements these paradigms by:
- Improving system throughput in high-volume APIs
- Reducing contention in shared data stores
- Supporting real-time read/write scaling
- Enabling eventual consistency and resiliency through asynchronous processing
Real-World CQRS Example: Scalable Shipment Integrations
Let’s understand how CQRS is applied in a real-world scenario using MuleSoft.
A global logistics provider wants to integrate its shipment system with external applications, where the system must handle high volumes of both read and write operations concurrently. The core object is a Shipment, and there are two high-traffic operations:
- Booking Shipments (Command) – Clients use the Mule application to create new shipments.
- Tracking Shipments (Query) – Clients frequently track existing shipments.
The read-to-write ratio is roughly 2:1, meaning for every booking request, there are approximately two tracking requests. With thousands of transactions per second, performance becomes a serious architectural concern.
Since the system of record is a database, indexing is a good way to speed up the tracking queries. But here’s the catch! While indexing the database improves read performance and makes shipment tracking fast, it slows down writes, degrading the booking performance.
CQRS Solution: Decoupling for Performance
To tackle this challenge, the architecture can be split into two specialized data stores:
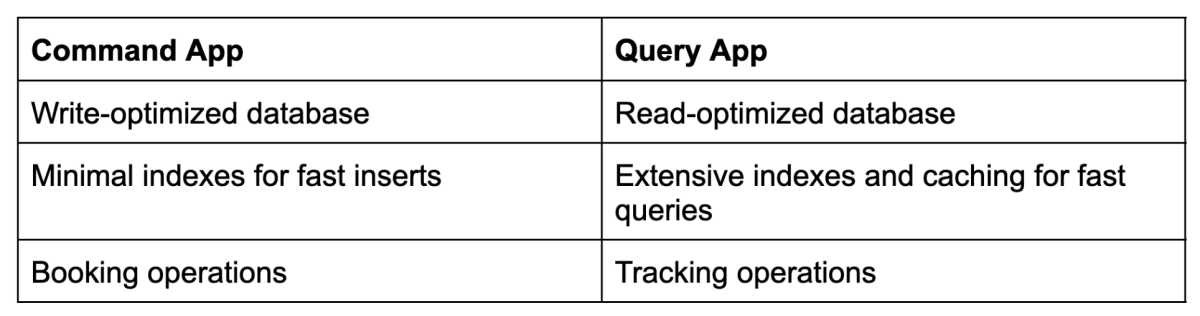
This eventual consistency model balances speed and accuracy while ensuring data flows between both data stores asynchronously.
But here’s the architectural dilemma: how to maintain data consistency between the two databases?
This is when we leverage the concept of eventual consistency with CQRS.
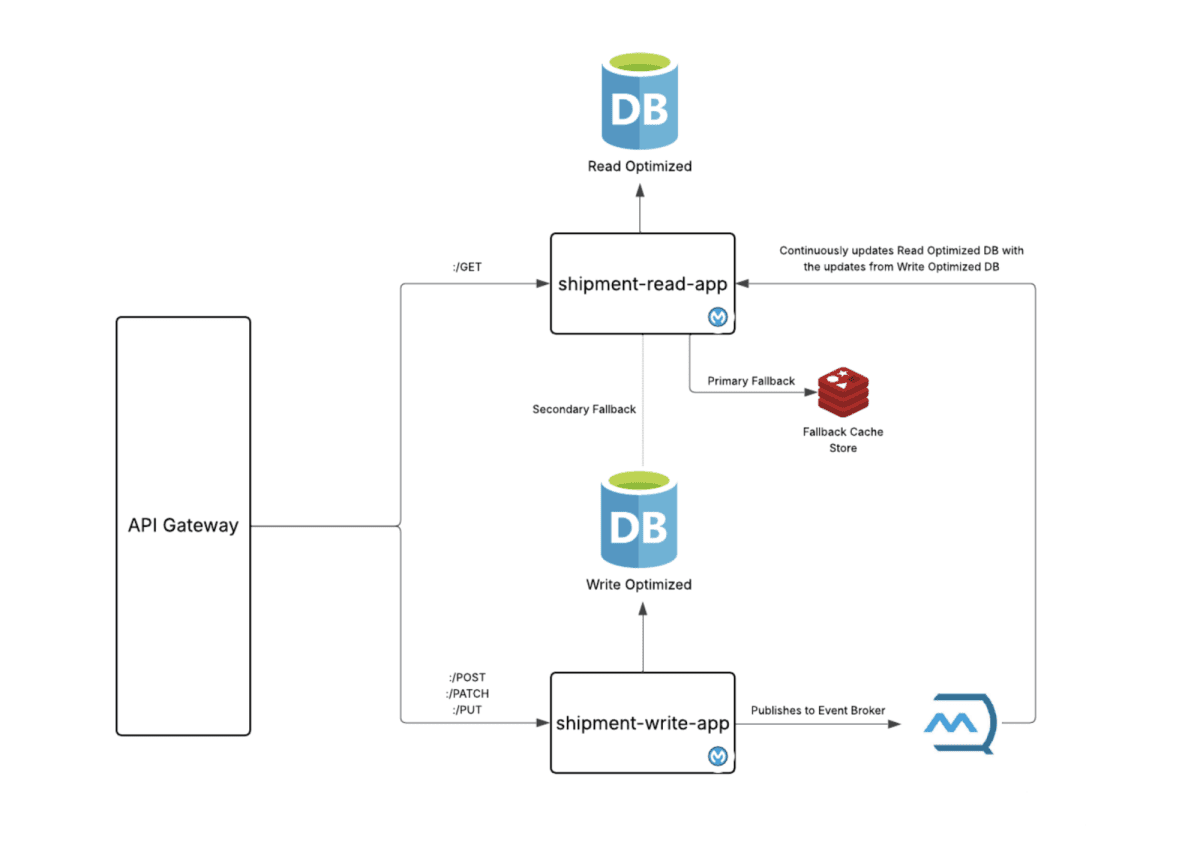
In the above design, the server layer interacts with the shipment-command-app for creating/updating/deleting shipment data and with the shipment-read-app for querying or tracking shipment status. Both apps are tied to write-optimized and read-optimized databases, respectively.
To ensure eventual consistency, the shipment-command-app pushes a copy of the data to a messaging broker like AnypointMQ or Kafka, which is then consumed by the shipment-read-app. The read-app then merges this data into the read-optimized database for users to query.
What If Data Isn’t Synced Yet?
Challenge arises when a user creates a shipment in the system and tries to track it even before the shipment is synced to the read-optimized database corresponding to the shipment-read-app. Here’s what happens in this situation:
- The shipment-read-app falls back to the write-optimized database to preserve the user experience.
- It manages to provide an appropriate response while also caching this response in key-value storages like Mule Object Store v2 or Redis with an adequate TTL.
- This ensures that the need for fallback doesn’t arise again until the read-optimized database receives the delta from the queue.
Key Benefits of CQRS in MuleSoft
Here are some of the benefits of integrating CQRS in MuleSoft:
- Scalability and Performance: Separate optimization paths for reads and writes create higher throughput and lower latency
- Maintainable and Modular Code: Decoupling business logic simplifies development, testing, and scaling individual services.
- Resilient Under Load: Event-driven syncing and fallback caching ensure availability even in high-traffic or failure scenarios.
- Cost Optimization: With well-managed data pipelines, infrastructure resources are used more efficiently, reducing overhead.
Conclusion
Adopting the CQRS design pattern within a MuleSoft-based architecture helps build solutions that are not only scalable and high-performing but also easier to manage and evolve. By separating the read and write workloads, your architecture becomes more resilient, scalable, and maintainable, further unlocking greater control over system behavior under load.
In a world of increasing data and transaction volumes, leveraging CQRS with MuleSoft is a strategic move toward delivering resilient, future-ready integration solutions.
To read more on such insightful topics, click here.
Recent Blogs

Architecting Scalable Integrations with CQRS Pattern in MuleSoft
Modern integration and distributed systems demand scalability and modularity. As...…

Connecting MuleSoft and Azure SQL with Entra ID
Introduction Establishing a secure connection between MuleSoft and Azure SQL Da...…

Understanding Salesforce Flow Approval Processes
Introduction: Salesforce introduced Flow Approval Processes in the Spring '25 re...…

Capturing Real-time Record Updation Using LWC
Introduction In modern CRM ecosystems, real-time Salesforce integration and s...…

All About Schedulers: Mule 4
In the world of Mule 4, automating repetitive tasks and triggering flows at defi...…

Demystifying CloudHub 2.0 Networking
CloudHub 2.0 is the latest version of MuleSoft's powerful managed runtime platfo...…
Learn how MuleSoft & Salesforce helps businesses create incredible digital experiences. Speak with one of our consultants today
Let's Work Together